
Get a Quote
Please fill in the form and we will get back to you soon!
We appreciate you contacting iWave.
Our representative will get in touch with you soon!
Get in Touch
We appreciate you contacting iWave.
Our representative will get in touch with you soon!
Unleashing Edge Intelligence on XILINX FPGA through Corazon-AI

The Rising Need for EdgeAI
Traditionally, Artificial Intelligence Solutions have all been dependent on the cloud with most of the data filtering, pruning, and computing taken care on the cloud. Now, there is a need for real-time pre-emptive action in industries and smart cities with decision and computation on the edge.
Speed and Privacy are now the key parameters critical in Artificial Intelligence Solutions across industries and verticals impacting the choice of technology on the edge. Applications ranging from medical imaging to intelligent traffic management, there is now a need for high-performance intelligent devices featuring increased hardware acceleration and decreased latency.
To meet the growing requirement of EdgeAI devices and the strong proposition of an FPGA on the edge, iWave has launched Corazon-AI, an Edge AI Solution built around the Xilinx Zynq® UltraScale+™ MPSoC.
AI Engine on an FPGA, GPU and CPU
To make the most out of the AI Engine on CPU Cores, frequency scaling was adopted to achieve acceleration, which was followed up by an increase in the number of processor cores to scale up performance. This was a challenge for programmer to target multi-core platforms and optimise his models. This gave rise to GPU which provided for a massive parallel array solution to integrate an AI Engine.
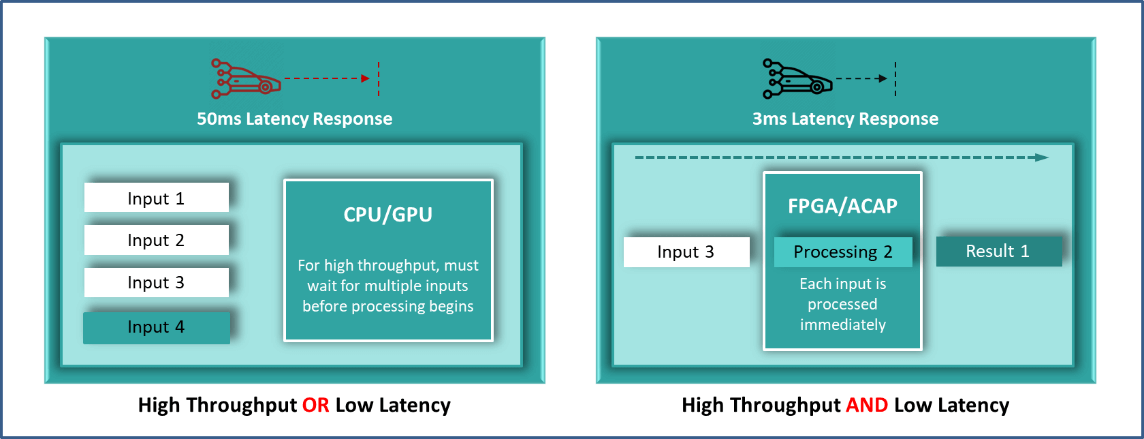
Achieving through-put coupled with a high batch size awaiting all inputs before getting initiated on the processing, paving the way for increased latency. There is a compromise of performance and latency on GPU solutions, giving developers a tough decision to make. The AI Engine on an FPGA provides for more parallelism increasing the AI Engine capability while achieving a better through put with a reduced batch size. FPGA can hence provide the resolve for the compromise between performance and latency.
While the AI engine runs on the FPGA, the processing functionality can be customized at the base logic port level. The configuration enables direct access to hardware I/O without the impending latency of internal bus structures. This provides immediate high-latency processing of data from a special hardware interface and real-time action on input data. This makes FPGA more responsive and allows for more dedicated special-purpose innovation operations.
Therefore, FPGA seems to be the front-runner while analysing the flexibility, latency, performance and optimisation and deem to be an ideal fit for AI on the edge.
Corazon -AI – The heart of AI
Corazon-AI has an integrated Xilinx® FPGA AI engine called DPU (Deep Learning Processor Unit) to perform the AI application acceleration. The DPU is a configurable computation engine dedicated and optimized for convolutional neural networks.
Corazon-AI has the interfaces to connect to 8 IP Cameras, multiple USB Cameras and an SDI Camera. The ability to capture multi-angle high-resolution video frames that are proactively processed by the in-built AI Inference engine add further strength.
With the support for high-speed connectivity such as Dual Gigabit Ethernet and multiple wireless connectivity options such as Wi-Fi , Bluetooth and Cellular connectivity, the device can communicate to the cloud and servers when necessary and is modular in architecture.
An ideal application for Corazon-AI would be an intelligent toll management system. With the provision to connect 8 IP Cameras, cameras across lanes can capture individual images and video streams and running models simultaneously on each of the input streams. Decisions and data filtering can be done on the edge and eliminates the need to have multiple gateways at each toll plaza. At present, the whole video stream is transferred from the toll to the control centre where the decision and processing can take place.
Corazon-AI can provide for an ideal fit in applications where there is a need to connect multiple cameras and a need for computing and data-driven decisions on the edge such as Traffic Management, Video Surveillance, Smart Parking and automated video inspection sorting .

DPU helps achieve High Through-Put and low latency:
The DPU has configurable hardware architectures (B512, B800, B1024, B1152, B1600, B2304, B3136 & B4096). Each DPU architecture capable to configure up-to 3 internal cores. Also, Dedicated AXI interfaces are provided for instruction access, configuration access and data access. The Data access AXI master interface supports configurable width of 64 or 128 bits which are capable of convolution, deconvolution and Depth wise convolution.
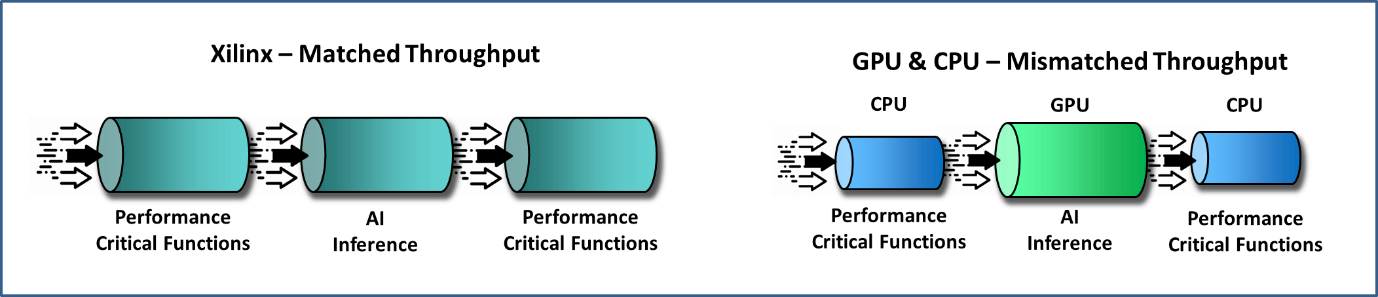
Figure 1: DPU’s peak theoretical performance with different configurations.
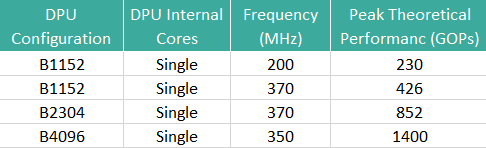
Figure 2: Performance of Several Models
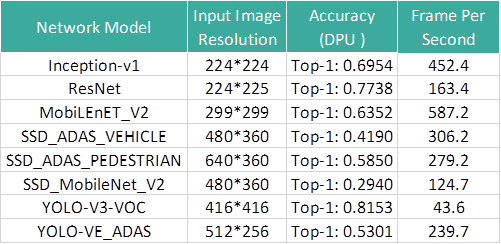
*These models were pruned using the XILINX pruning tool
* The accuracy is based on an 8-bit fixed quantization
* Measured on Corazon-AI platform with single B4096 core with 16 threads
About iWave Systems Technologies Pvt. Ltd.:
About iWave Systems: iWave Systems Technologies Pvt. Ltd., , established in 1999, focuses on product engineering services involving embedded hardware and software, FPGA design and development. With over 18 years’ experience on FPGA, provides custom design services and a wide array of XILINX System on Modules – ZYNQ 7000 Series and Ultra Scale+ MPSoC series.
You can get in touch with us for enquiries and further information at mktg@iwavesystems.com
iWave is an embedded systems engineering and solutions company, designing solutions for the Industrial, Medical, Automotive and Avionics vertical markets, and building on our core competency of embedded expertise since 1999. Read More…